Running LLMs Locally: Performance Gains for Backend Development Without Cloud Costs
Compare lightweight local models versus cloud APIs for Node.js and Java Spring Boot services focused on speed and privacy.

Running LLMs Locally: Performance Gains for Backend Development Without Cloud Costs
Backend teams keep hitting the same wall. Cloud bills for language model features climb every month, and response times stay hostage to network conditions. The good news is you can move inference inside your own services now. Local models cut both the variable fees and the extra latency that cloud calls always add.
That shift matters most for teams already working in Node.js or Java Spring Boot. You get predictable speeds and keep user data inside your own infrastructure.
Why Cloud LLM Costs Keep Climbing for Backend Teams
Token pricing looks cheap on paper until real traffic hits. A single endpoint that handles user questions or generates responses can push monthly charges well past the basic subscription once volume spikes. Add the 200 to 800 milliseconds of network round-trip time and the picture gets worse fast.
Real-time services feel the pain first. API gateways and recommendation engines written in Node.js or Java Spring Boot lose their edge when every inference leaves the server. Data egress charges and extra compliance checks for sending prompts outside the VPC pile on top. Many teams are now asking whether every workload still belongs in the cloud.
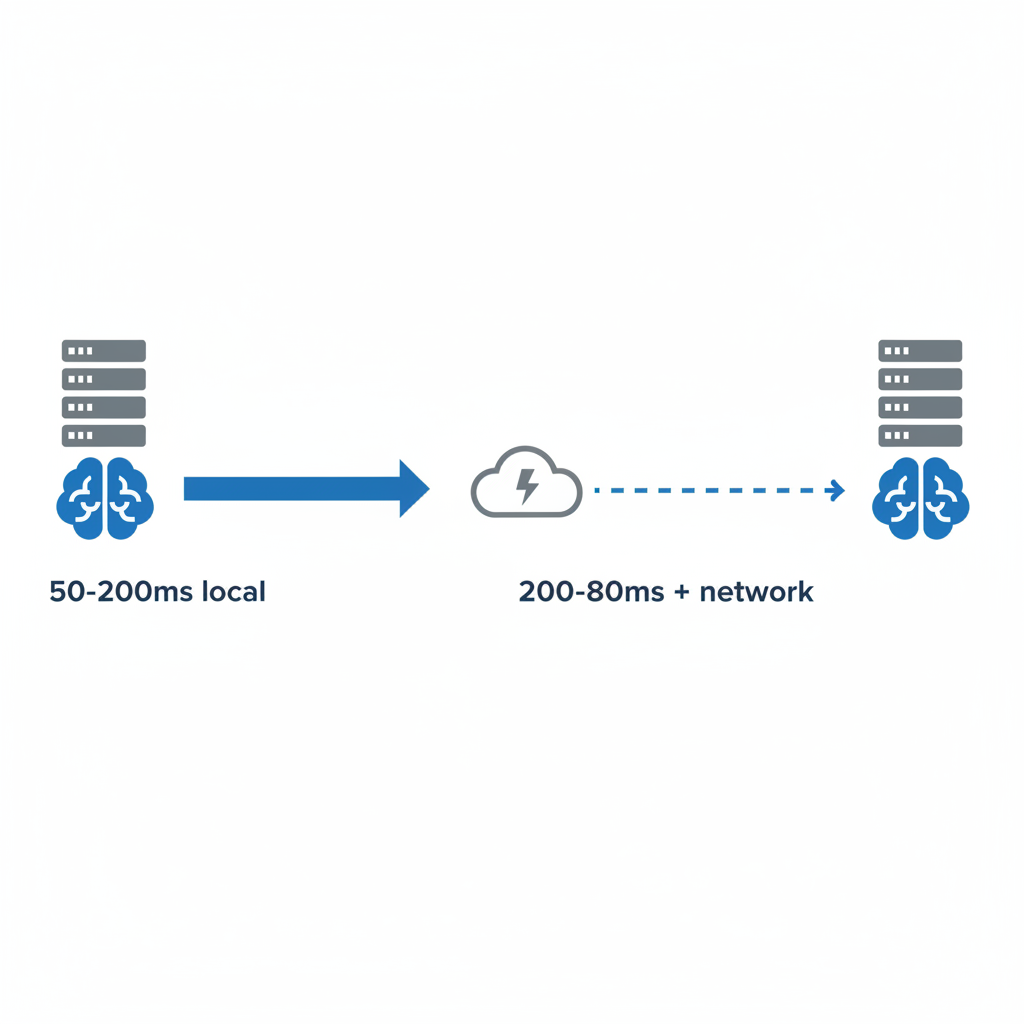
Performance Gains for Backend Development When You Run Models Locally
Local inference removes the network hop completely. Response times become steady instead of swinging with provider load. On decent hardware, smaller models can deliver around 100 tokens per second on Mac systems. Cloud versions of similar models often sit between 30 and 60 tokens per second before you even count the network delay.
Node.js services can batch prompts inside the same process and cache common outputs in memory. Latency drops into the 50 to 200 millisecond range on consumer hardware. That difference shows up clearly in services that must meet strict response windows, such as authentication checks or live data enrichment.
Accuracy stays close enough for most backend tasks. Local models reach 85 to 95 percent of larger cloud models on common reasoning tests. The real win comes from removing external dependencies so your service container stays in control of throughput.
How Local Models Keep Data Inside Node.js and Spring Boot Services
Running inference inside the application means prompts never leave your VPC or cluster. That setup lines up cleanly with GDPR, HIPAA, and SOC2 rules because you avoid handing audit logs to a third party.
Node.js and Spring Boot projects can integrate local inference libraries directly into the application process. This allows swapping cloud clients for local ones with only small code changes. The attack surface shrinks to your own service boundaries.
Cost Comparison: Local LLMs Versus Cloud APIs
Hardware and electricity replace per-token charges. Reports put the running cost between $0.001 and $0.04 per million tokens once the machine is paid for. At steady volumes around 30 million tokens a day, the hardware pays for itself in a few months. Teams handling 50 million tokens monthly often see the total cost of ownership cross over in roughly 18 months.

The math works best when traffic stays fairly consistent. Burst-heavy workloads still lean toward cloud APIs, but most internal backend jobs run at a predictable pace that favors fixed hardware costs.
Choosing and Integrating Lightweight Models with Node.js and Spring Boot
Start with suitable lightweight local models. These handle the majority of backend jobs without demanding enterprise GPUs. Integration happens through appropriate local inference libraries for Node.js and Spring Boot.
Both libraries give you familiar completion endpoints, so existing service code needs little rewriting. Quantized versions cut memory use while keeping performance within that 85 to 95 percent band of the bigger models.
Hardware Requirements That Actually Work
A practical starting point is consumer-grade hardware with sufficient memory for the chosen model size. Production loads need extra room for longer contexts and multiple requests at once. Using reduced precision representations can lower memory needs and speeds things up with only a small accuracy trade-off.
Keep context windows moderate if you want to stay in the low latency range. Always benchmark real token throughput under load rather than trusting peak numbers. Sustained traffic reveals hardware limits that cloud dashboards hide.
Getting Started Without Overcommitting
Pick one non-critical service first. Measure latency and spend for two weeks, then compare against the cloud baseline. Most teams find the biggest wins in internal tools or features that already run at steady volume. Once you see the numbers, you can decide whether to expand or keep the hybrid approach.
Maintenance stays lighter than people expect. Model files update on your schedule, and you control which versions run in production. The main ongoing tasks are monitoring GPU temperature and watching for new quantized releases that improve speed.
Local inference also opens simple experimentation. You can test prompt variations or fine-tune small adapters without racking up cloud charges. That freedom often leads to better domain-specific results than generic cloud models deliver.
After the first pilot, the decision usually comes down to traffic patterns and data sensitivity rather than raw capability. Many backend teams end up running a mix: local models for steady internal work and cloud APIs only for the occasional high-complexity request.
Related Articles

How Twitter's AI Translation Is Breaking Language Barriers for Global Software Engineering Teams

Building Backend Systems with Java Spring Boot for Embodied AI in Robotics Startups
Markdown Mastery: Crafting Transmit-Ready Docs for Backend Development Projects
