Cloud Computing Difficulty Breakdown: Conquer Hard Concepts Like Disaster Recovery
Ranked guide to cloud computing essentials from easy VMs to tough high availability design, with actionable steps for backend developers to build resilient systems.

Cloud Computing Difficulty Breakdown: Conquer Hard Concepts Like Disaster Recovery
Why do cloud computing concepts like disaster recovery still trip up experienced backend developers and DevOps engineers, even after mastering system design basics? Backend systems fail under pressure. Without a clear path through cloud complexity, resilience stays out of reach.
By the end of this guide, you'll have a difficulty-ranked breakdown of cloud computing concepts with actionable steps to implement high availability and disaster recovery strategies. You'll build resilient, scalable backend systems that withstand outages. Mastering these, from basic virtual machines to complex disaster recovery, matters for backend developers crafting systems that scale and survive.
Level 1: Essential Cloud Computing Fundamentals for Software Engineers
Start here to solidify your base. Virtual machines (VMs) and compute instances form the core of cloud infrastructure. Think of them as on-demand servers you provision via APIs, like EC2 instances on AWS or Compute Engine on GCP. For backend apps, spin up a VM for stateless services: pick instance types based on CPU, memory, and GPU needs, then attach storage.
Next, grasp storage types. Object storage, such as S3, handles unstructured data like images or logs in your app. It's durable, scalable, accessed via HTTP. Block storage fits databases or file systems needing low-latency I/O, mounting as volumes to VMs. Use object for backups, block for active workloads.
Core networking seals it. Virtual Private Clouds (VPCs) isolate your resources. Subnets divide them logically across availability zones for redundancy. Security groups act as stateful firewalls, controlling inbound traffic by port and IP. Actionable step: Deploy a VPC with public/private subnets, add security groups allowing only port 443 from your load balancer. These fundamentals prevent common missteps, setting you up for scalable backends.
Level 2: Tackling Intermediate Backend Development Challenges in the Cloud
With basics down, scale your apps. Load balancers evenly distribute incoming traffic across instances, handling spikes without overload. Application load balancers route by HTTP headers or paths, ideal for microservices.
Auto-scaling groups adjust instance counts dynamically based on metrics like CPU use. Set min/max bounds and scaling policies, say, add instances at 70% CPU, to match demand.
Serverless shifts ops burden. Functions like Lambda run code on events without managing servers. Pair with managed databases such as RDS or DynamoDB, which handle patching and backups. For a backend API, deploy serverless endpoints fronted by API Gateway.
Actionable: Configure an auto-scaling group behind a load balancer, integrate a managed PostgreSQL instance. This cuts ops overhead, letting you focus on code. These tools bridge to high availability, where mastering cloud concepts ensures backend resilience.
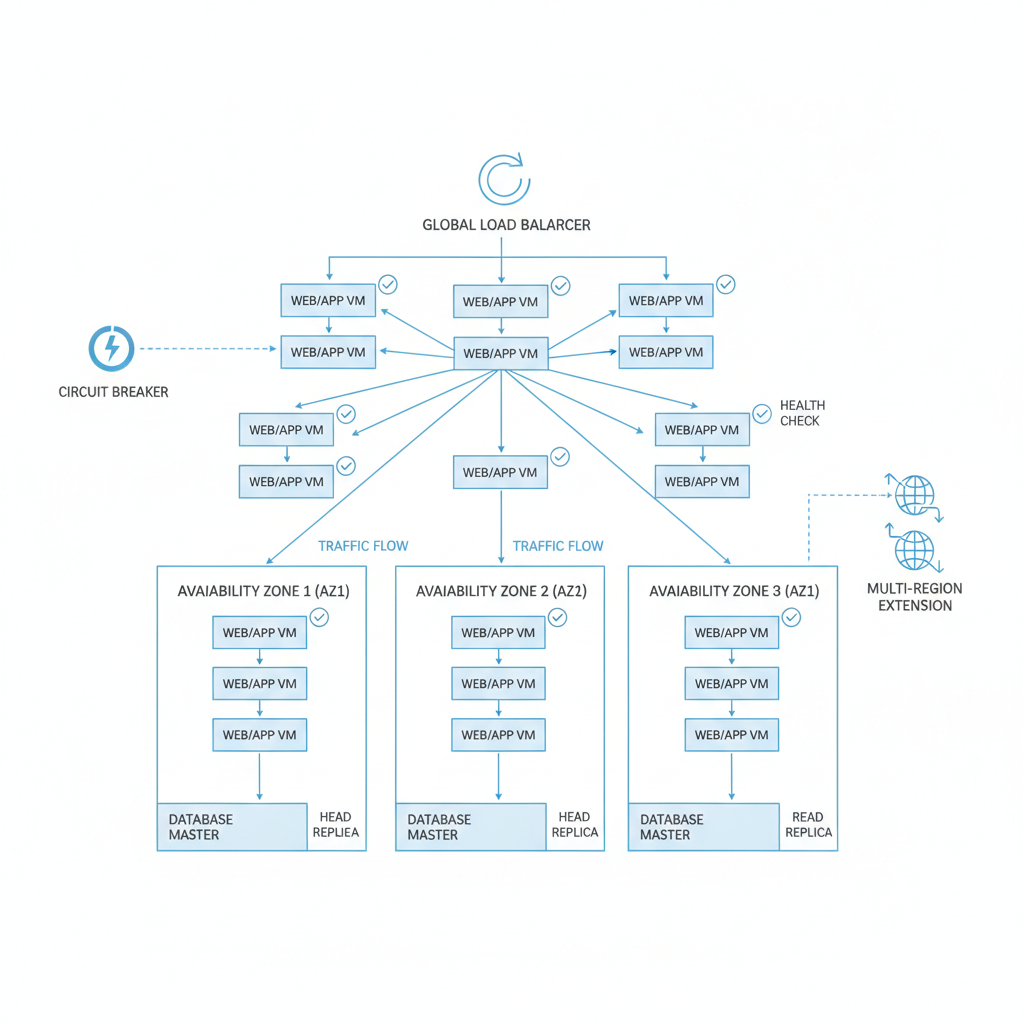
Level 3: Designing High Availability Architectures for Cloud Systems
Resilience demands redundancy. Deploy across multiple Availability Zones (AZs) within a region to survive data center failures. Stretch to multi-region for broader protection.
Databases need read replicas to offload queries and enable failover. Promote a replica to primary in seconds during outages.
Health checks probe endpoints; failing ones trigger removal from rotation. Circuit breakers halt calls to unhealthy services, preventing cascades.
Actionable steps: Architect your app with multi-AZ load balancers and read replicas. Implement health checks returning HTTP 200 only on success, add circuit breakers via libraries like Resilience4j. Test by terminating instances.
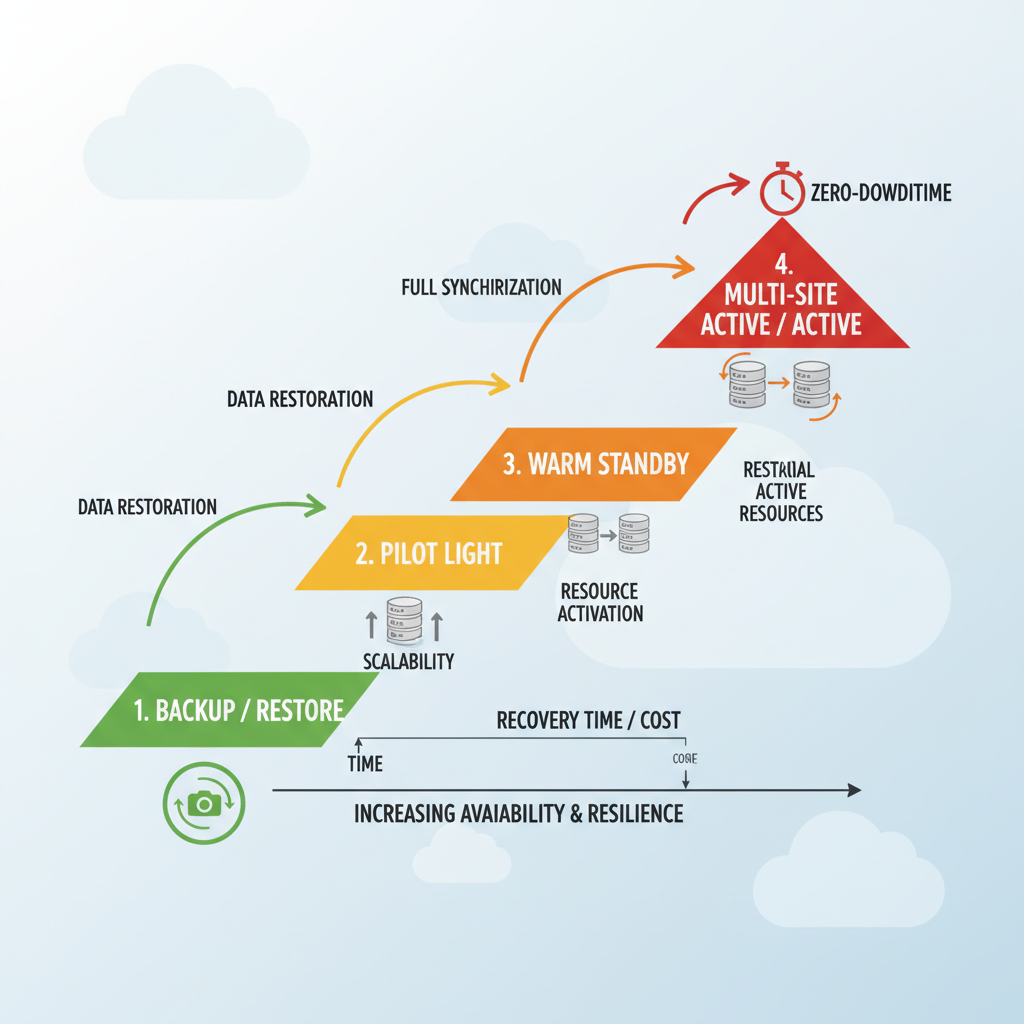
What is Disaster Recovery in Cloud Computing?
Disaster recovery (DR) restores operations after failures, from cyberattacks to outages. Common patterns include:
- Backup and restore: Cost-effective snapshots for basic recovery.
- Pilot light: Minimal always-ready resources to scale up quickly.
- Warm standby: Near-live setup for faster scaling.
- Multi-site active/active: Zero-downtime across sites.
Essential steps start with assessing infrastructure and conducting business impact analysis. Pick a provider that fits. Key components:
- Define requirements.
- Identify suitable vendors.
- Implement and test.
- Consider on-premises options if needed.
Integrate into DevOps pipelines for automation. Pitfalls? Untested plans fail. Regular testing validates effectiveness and uncovers issues. Document runbooks for clear recovery steps, reducing stress.
How Do RTO and RPO Shape Effective Disaster Recovery Planning?
RTO is the maximum tolerable downtime before restoration. RPO measures acceptable data loss in time. Align them with SLAs: e-commerce might demand RTO under one hour, RPO minutes.
Cloud trade-offs balance costs, multi-site active/active hikes bills but cuts RTO. Understand vendor agreements for performance and recovery costs.
Actionable: Audit your app's tolerance. Target RPO via frequent snapshots, RTO with pilot light. This metrics-driven planning empowers backend teams.
Top Tools and Best Practices for Automating Cloud Resilience in DevOps
Automation cuts recovery time and errors, enabling repeatable failovers. AWS Route 53 handles DNS failover. RDS snapshots and Backup service automate restores. Terraform codifies infrastructure as code (IaC) across clouds. Kubernetes orchestrates containers with built-in HA.
Test via chaos engineering, inject failures with tools like Gremlin, and monitor with Prometheus or CloudWatch.
Best practices: Version runbooks, automate pipelines, test quarterly. Actionable: Write Terraform for multi-region DR, deploy Kubernetes with pod disruption budgets, run chaos drills.
You've climbed the cloud computing difficulty ladder, from fundamentals to mastering disaster recovery. Apply these backend development and DevOps strategies today to design systems that scale and survive. Run your first DR simulation. Watch resilience soar, your resilient cloud journey starts now!
Related Articles

Hybrid Cloud Deployment Models for Banks Handling Regulated Data
Shifting from Centralized Cloud Computing to Distributed Compute Models

Edge AI Deployment on Cloudflare Workers: Cutting Latency and Costs for Developer Productivity in Cloud Computing
